
This is a pivotal step forwards in Cloud based deep learning; for the first time, data scientists can access the unprecedented acceleration of the NVIDIA A100 Tensor Core GPU via AI Platforms' Deep Learning Containers.
In this article we provide an introduction to Google’s AI Platform and Deep Learning Containers, before exploring the astonishing performance of the A100 GPU.
Google Cloud AI Platform
For those of you not familiar with AI Platform, essentially it’s a suite of services on the Google Cloud Platform specifically targeted at building, deploying and managing machine learning models in the Cloud.
AI Platform is designed to make it easy for data scientists and data engineers to streamline their ML workflows. We use it a lot with AutoML (Google’s point-and-click ML engine) but in addition it supports the training, prediction and version management of advanced models built using Tensorflow.
Take advantage of Google's expertise in AI by infusing our cutting-edge AI technologies into your applications via tools like TPUs and TensorFlow.
Google Cloud
Cloud AI Platform Services
AI Platform has a suite of services designed to support the activities seen in a typical ML workflow.
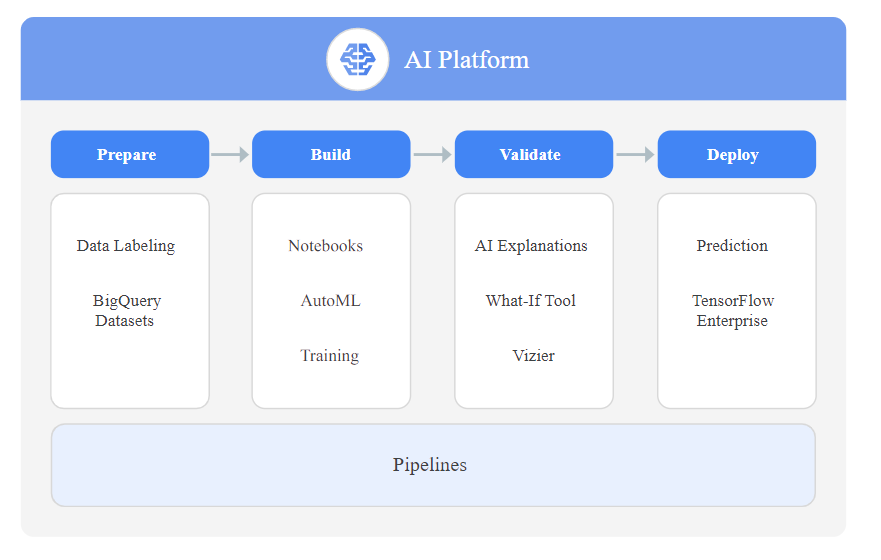
In this article we will be focusing on Deep Learning Containers (these fall under the Pipeline section in the diagram above). Whilst the other services are out of scope for this article, we have included a brief description of each together with some links in case you would like to learn more.
1. Prepare
We typically first prepare (ingest, cleanse, feature engineer) our data in BigQuery Datasets, collections of tables in Google Clouds hyper-scale data warehouse.
Google offers a Data Labelling Service for labelling training data
(typically we use for classification of images, video, audio and text).
2. Build
We’ve already mentioned AutoML, the zero code platform for training models.
We use AI Platform Notebooks (hosted Jupyter Notebooks) for building custom models (typically Tensorflow or SkLearn).
Finally, we use AI Platform Training for convenient model training.
3. Validate
Explainable AI is a great suite of tools that helps you understand your model’s outputs, verify the model behavior, recognize bias in your models, and get ideas for ways to improve your model and your training data. This really helps to take the guesswork out of activities such as model tuning.
AI Platform Vizier takes this a step further, and offers a black-box optimization service, to tune hyperparameters and optimize your model’s output.
4. Deploy
Whether you have a model trained using no-code AutoML, or an advanced Tensorflow model built using AI Platform Notebooks, AI Platform offers a number of services to help deploy models and generate predictions.
AI Platform Prediction manages the infrastructure needed to run your model and makes it available for online and batch prediction requests.
AutoML Vision Edge helps deploy edge models (run on local devices e.g. smart phone, iOT device) and can trigger real-time actions based on local data.
TensorFlow Enterprise offers enterprise-grade support for your TensorFlow instance.
5. ML Pipelines (ML Ops)
ML Ops is the practice of deploying robust, repeatable and scalable ML pipelines to manage your models. AI Platform offers a number of services to assist with these pipelines.
AI Platform Pipelines provides support for creating ML pipelines using either Kubeflow Pipelines or TensorFlow Extended (TFX).
Continuous evaluation helps you monitor the performance of your models and provides continual feedback on how your models are performing over time.
Deep Learning VM Image supports easy provisioning of Cloud VMs for deep learning ML applications.
Finally, Deep Learning Containers, provides preconfigured and optimized containers for deep learning environments.
Deep Learning Containers
AI Platform Deep Learning Containers provides you with performance optimized, consistent environments to help you prototype and implement workflows quickly. Deep Learning Container images come with the latest machine learning data science frameworks, libraries, and tools pre-installed.
Google Cloud
It’s easy to underestimate how much time it takes to get a machine learning project up and running. All too often, these projects require you to manage the compatibility and complexities of an ever-evolving software stack, which can be frustrating, time-consuming, and keep you from what you really want to do: spending time iterating and refining your model.
Deep Learning Containers were designed to accelerate this process.
All Deep Learning Containers have a preconfigured Jupyter environment, so each can be pulled and used directly as a prototyping space. First, make sure you have the gcloud tool installed and configured. Then, determine the container that you would like to use. All containers are hosted under gcr.io/deeplearning-platform-release, and can be listed with the command:
|
|
|
|
Then, the running JupyterLab instance can be accessed at localhost:8080. Make sure to develop in /home, as any other files will be removed when the container is stopped.
If you would like to use the GPU-enabled containers, you will need a CUDA 10 compatible GPU, the associated driver, and nvidia-docker installed. Then, you can run a similar command.
|
|
|
|
And now you simply develop your model using this container.
NVIDIA A100 Tensor Core GPU
So, now you’re orientated with Google Cloud AI Platform and it’s Deep Learning Containers, let’s explore a Cloud first; the ability to access a Deep Learning Container powered by the NVIDIA A100 Tensor Core GPU.
The A100 GPU. Accelerating the Most Important Work of Our Time.
Nvidia
So what does that actually mean in real world terms?
The first thing to note is this line of GPUs were specifically designed with deep learning and other applications of high-compute AI in mind. The second thing to note is compared to it’s predecessor, the A100 provides up to 20X higher performance with zero code changes. That’s a massive leap.
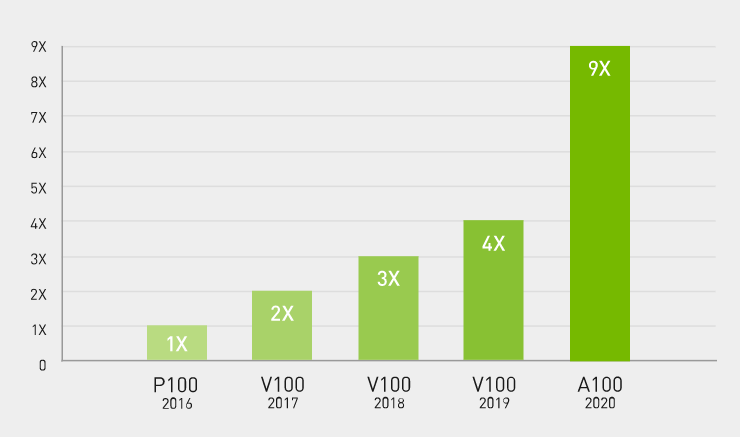 A100 GPU technical specification
A100 GPU technical specification
Highlights of the A100’s data sheet include:
- 40GB of GPU memory
- 1.6 TB/sec memory bandwidth
- 312 teraFLOPS of deep learning (20x that of predecessor)
- 250W-450W max power consumption
- structural sparsity architecture of the A100s Tensor Cores supports up to 2x performance gains for “sparse” models (models who’s parameter sets contain lots of zeros, great for NLP applications).
And if one of these powerhouses isn’t enough for your use case, don’t worry because thanks to some clever SDK support from NVIDIA, these will scale to 1,000s of A100 GPUs.
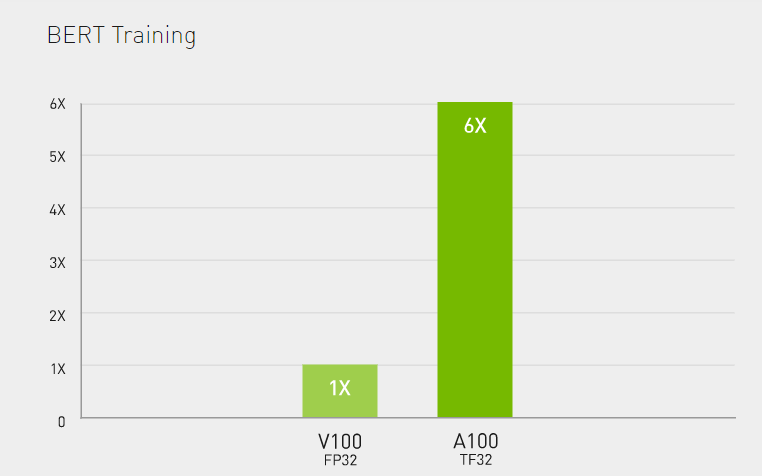
Benchmarking the A100; training BERT
BERT stands for Bidirectional Encoder Representations from Transformersis. Recently published by Google, BERT is a natural language processing (NLP) ML model. BERT is frequently used for benchmarking due to the high-compute needed to fully train the model.
The A100 produced some astonishing results:
So what are the A100 options available in Google Ai Platforms’ Deep Learning Containers?
A whopping 16 GPUs per VM
For demanding workloads, you can opt for the the a2-megagpu-16g Deep Learning Container. With 16 A100 GPUs, this offers an astonishing 640 GB of GPU memory and providing an effective performance of up to 10 petaflops of FP16 or 20 petaOps of int8 in a single VM when using the new sparsity feature. Wow. We had to read these numbers twice.
Then we had to double-take on the system memory; a whopping 1.3 TB. And don’t worry about any bottlenecks accessing it, the memory bus supports up to 9.6 TB/s.
Enough to consume the most demanding of workloads.
Of course, A100 powered VMs are available in smaller configurations too, allowing you to match your application’s needs for GPU compute power.
Next steps
1. Read the Google Cloud AI Platform release notes
2. Learn more about Ancoris Data, Analytics & AI